Single Application with Namespaces
Feature groups
The v3 commit moves classes into feature groups or
bounded contexts. The benefits of bounded
contexts are readability and a step toward isolated (loosely coupled, highly cohesive) components.
Why is readability important?
Imagine you've just joined the team and pulled the next story from the top of the backlog, Update
Timesheets. With functional groups, you would have to scan the entire codebase for timesheet related file
changes. As the size of your codebase increases, the potential to overlook associated files that also need
updating increases. Again, this is especially true as codebases increase in both size and complexity. Using
feature groups or bounded contexts, all the timesheet related files are in one place with any complexity
confined to a single directory.
The step toward single responsibility directories, while small, positions the codebase for v4, individual
components.
Design decision We've avoided the use of a "common" or "util" directory in
favor of, in this case, jdbc-support and rest-support directories. Common or Util tells the reader
absolutely
nothing about the containing classes other than they may be shared by every class in the codebase. Avoiding
common, util or similar "generic" directories will allow you to evolve your codebase on a moment's notice.
Design decision Database tests re-query the table data after data creation to
ensure that records are actually persisted in the database.
Design decision Test package names are different than source package names.
This is to ensure the intended level of encapsulation and reveal accidental design choices. It should be
extremely painful for people to test package / private methods.
Single Application and Components
Components
In the v4 commit we've extracted the Users, Accounts, and Projects components. We've also extracted
components for rest-support and jdbc-support, making a conscious effort to avoid creating a "common"
package.
The main characteristic of the v4 commit is that each component is individually built and tested. This is
similar to feature groups (loosely coupled and highly cohesive). Dependencies are clearly described within
the build file and circular dependencies are resolved. The v4 commit sets us up nicely to introduce
Services.
We've created a single databases directory although this is slightly atypical. Data definition language
within each component is more common, permitting a per component data store.
Design decision We've chosen to create a Jdbc Template over an Object Relational
Mapping library. This is because the bidirectional nature of JPA or similar libraries can lead to the
accidental introduction of circular dependencies which make it painful to evolve a codebase. Database tables
are not necessarily Objects and you shouldn't think about them as such.
Multiple Applications and Components
Applications
The v5 commit introduces 4 distinct applications - Allocations, Backlog, Registration, and Timesheets.
The Registration Application includes a simple REST API to access Account, Project, and User information.
The service itself is very minimal, leaving domain logic within components. The Allocations, Backlog, and
Timesheets Applications include a REST API, domain logic, and persistence layer. An alternate structure
might have been to create components for each feature group similar to the Registration Application.
Single Repository
You'll notice that we've maintained a single Git repo. The single repo significantly reduces the
overhead and complexity of API (in-process) versioning while enabling cross-component refactorings. The
assumption is that Applications are stateless, well-tested, and able to be deployed with the larger
suite of Components and Applications regardless of any local changes. They are also only consumed by the
single "large" system. We understand that this topic is slightly controversial although, we highly
encourage you to explore having a single repository.
So why would I do this?
A single repository may be beneficial for co-located teams of 6-8 people supporting multiple
applications or a distributed system where the overhead associated with managing multiple repos and
versioning libraries hurts feature velocity more than the benefits received from autonomy. Be careful
not to shift early energy from delivering features - to coordinating repositories and libraries.
As your team grows and has natural splits - moving to multiple repos may quickly follow. This especially
holds true when teams are no longer co-located and shared libraries lose domain specific knowledge -
i.e. shared libraries are now simply support libraries.
The transition from step v4 to v5 shouldn't be taken lightly. The move to microservices is more than
just an implementation detail and requires real and continued attention. Service availability (retry) and
versioning (especially deploying "breaking changes") are just a few of the topics that become top of mind
daily.
Design decision Components include both Record and Info classes.
This is to ensure that an individual component's public API is decoupled from its internal database schema /
implementation - i.e. you could change a component's underlying database technology or version an API
without impacting existing clients.
Design decision You'll notice that Controller classes are located within
each component. We've never found a strong reason to keep controllers or data access objects anywhere else
other than local to the component - i.e. everything you need to know about a given bounded context is in one
place. The design decision makes evolving the component to a microservice significantly less painful.
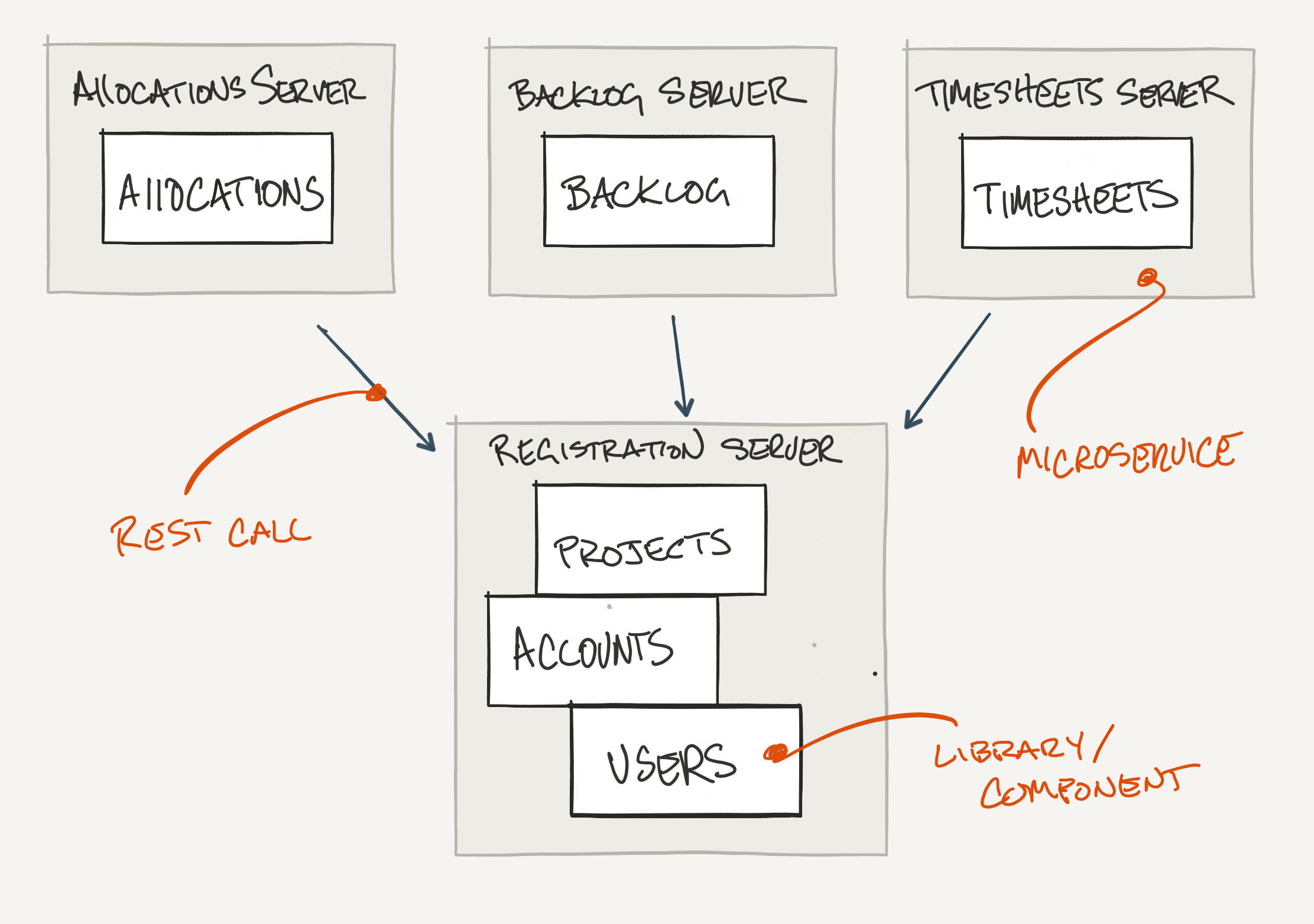
Service-to-Service Communication
Services
The v6 commit demonstrates a microservices architecture with service-to-service
communication - Allocations, Backlog and Timesheet applications
are dependent on the Registration service via REST.
We've found that scaling both teams and performance are typically the main drivers for moving components to
services for single systems; reuse, in this case, being another main driver. Reuse tends to be the main
driver for moving components to their own repository.
Lastly, you'll find an integration or acceptance test that "flows" through the suite of services and a
multi-service manifest file for deployment.
Design decision We've intentionally duplicated Info and Client classes in each
of the Allocations, Backlog and Timesheets components. While your first instinct might be to create a common
"project-client" or "domain" component, this duplication sets up for seamless versioning and moving
components to separate Git repos as your team grows.
Design decision You'll notice that we did not include or commit any
configuration or property files; user names, passwords, service location settings, etc. We've intentionally
left this to the environment ensuring that the same artifact could truly be deployed to any environment;
development, review, or production.
Databases
The v7 commit moves away from a single database to a database per microservice; Allocations, Backlog,
Registration, and Timesheets. Implementing a per component data store becomes increasingly important as you
evolve your application along the continuum to a distributed system. Service coupling has been completely
removed. Services are now able to manage their own persistence strategy (choice of database technology),
schema, and API versioning strategy independent of the other services.
Distributed Systems
Versioning
Versioning services naturally follows your initial microservices deployment. We've introduced the v8 commit
as a guide to service versioning. The Projects component, within the Registration service, has been upgraded
to support a new feature in Timesheets - only projects that are "funded" should allow for timesheet
submission. To support the new feature, you'll notice the duplication of Info and Controller classes within
the Projects component.
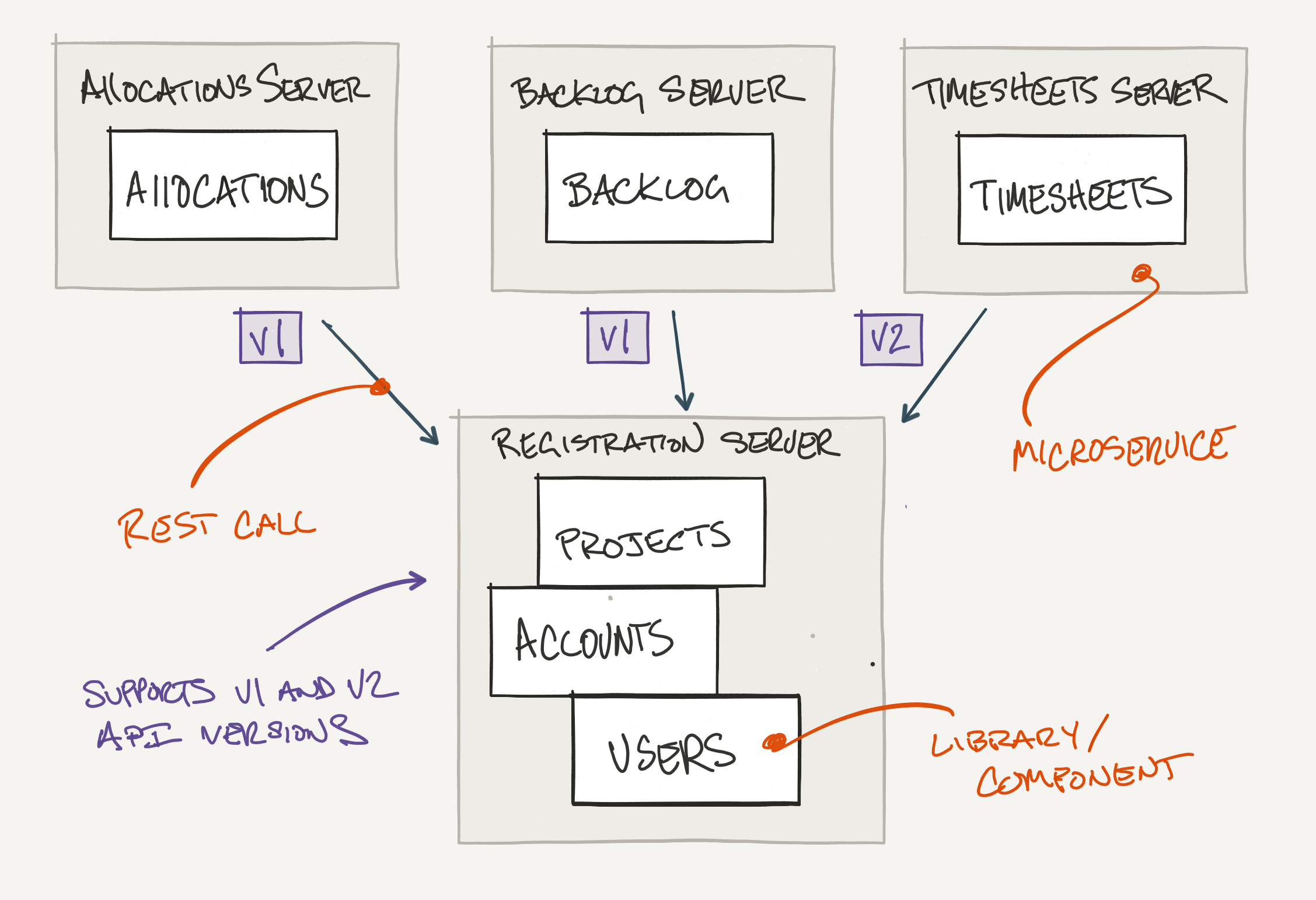
The V2 API is used by the Timesheet service while our 2 other services, Backlog and Allocations, continue to
use the V1 API.
Design decision We've used the Accept Header for my versioning strategy.
There are lots of debates around how best to publish a new API version; URL, Accept Header, Custom Header.
My recommendation is to simply choose the one that best meets your needs.
Service Discovery
The v9 commit removes the hard coded location of the Registration Service in favor of client-side service
discovery. Services register with the Discovery Server via a ScheduledExecutor - while ensuring a 30 second
heartbeat. We've implemented the Discovery Server using a standard Redis Set with key expiration.
Clients are able to discover services through a simple REST call - client side load-balancing is
realized by the random function that we've included on the List data structure. While trivial, the example
should give you insight into how service discovery works in practice.
Design decision We've chosen client-side service discovery over server-side
service discovery. Both patterns support service autoscaling, failures, and upgrades - as well as
dynamically assigned network locations.
Circuit Breaker
The v10 commit introduces the circuit breaker pattern. We've used a single-threaded Executor with a timeout
to demonstrate the basic behavior.
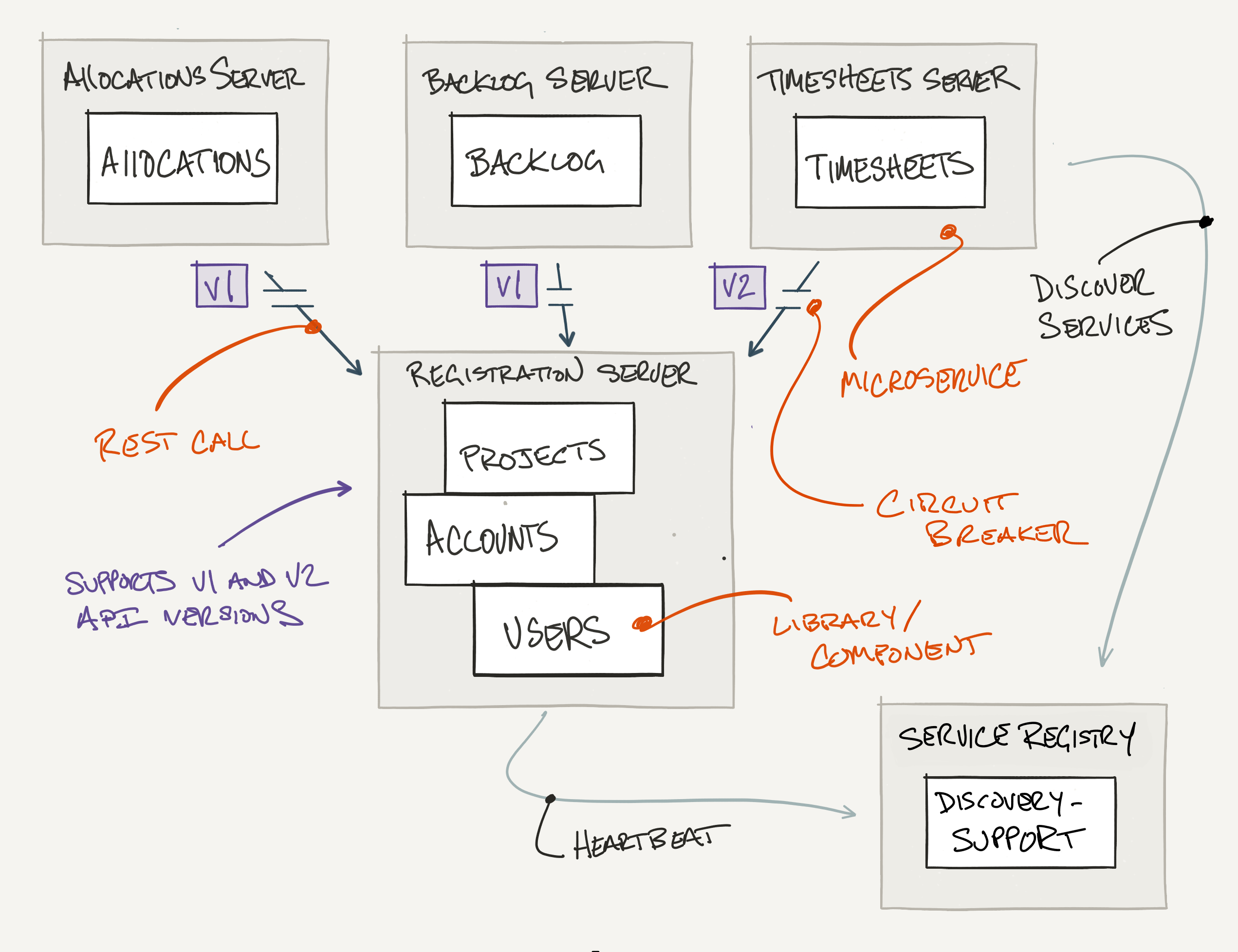
If the circuit is open and not ready for retry the circuit breaker will immediately call the fallback
function. If the circuit is closed the circuit breaker will call the desired block and only call the
fallback function when the maximum time to wait is reached. Typically there would be one instance per
commend that is thread-safe.
Early Design Considerations
We tend to start all new projects with the 3 top level directories - applications, components, and
databases. While following the continuum, we've found that the first few steps happen so quickly, weeks
versus months, that it is easier to start every project with a component based directory structure.
For Kotlin or Java projects, we tend to use gradle and include gradlew - resulting in the below initial
directory structure.
appcontinuum
├── applications
├── build.gradle
├── components
├── databases
├── gradle
├── gradlew
├── gradlew.bat
├── manifest.yml
├── README.md
└── settings.gradle
So why would I do this?
The components directory is a conscious effort to continually drive individuals toward a mindset of
loosely coupled, highly cohesive components. The directory helps you explicitly decide where you have
coupling between components and why. Components are compiled and tested independently - eliminating the
chance of introducing circular dependencies between components.
Summary
That's a wrap! Assuming you're on board with the continuum, we're hopeful the project has given you insight
in how an application evolves over time.
Applications may start anywhere on the continuum depending on how much information the team has at the start
of the project; greenfield applications without product-market fit may start left while big existing
re-writes may start on the far right. Functional groupings could prove challenging when evolving along the
continuum. Finally, it's also worth mentioning that not all applications need to evolve and could stop
anywhere on the continuum.
Thanks to barinek,
dajulia3, enocom,
shageman, and austinbv
for their early contributions.